
EN
3月20日至21日,“华为中国合作伙伴大会2025”在深圳盛大举行。本次大会以“因聚而生,众智有为”为主题,汇聚了来自五湖四海的行业翘楚、企业精英与技术专家,共同探讨如何携手并进,共谋人工智能发展。作为华为昇腾生态合作伙伴,易道博识携产品亮相本次盛会,现场展示适配华为昇腾芯片的大模型OCR解决方案。

近年来,数据已成为核心生产要素,而文档作为数据的重要载体,其智能化处理能力直接关系到企业的运营效率和决策水平。尤其是在金融行业,海量的业务文档,如合同、报表、凭证、证件等,构成了金融机构日常运营的血脉。如何高效、精准地处理这些海量文档,从中提取关键信息,并将其转化为可供业务系统使用的结构化数据,成为了金融机构数字化转型的关键挑战。
传统的OCR在处理结构化文档和印刷体文档方面已经取得了显著的成果,但在面对新版式、复杂版式文档等场景时,识别精度往往难以满足实际业务需求。此外,传统OCR系统通常需要针对不同的文档类型进行模型定制和训练,开发周期长、成本高昂,难以适应快速变化的业务需求。
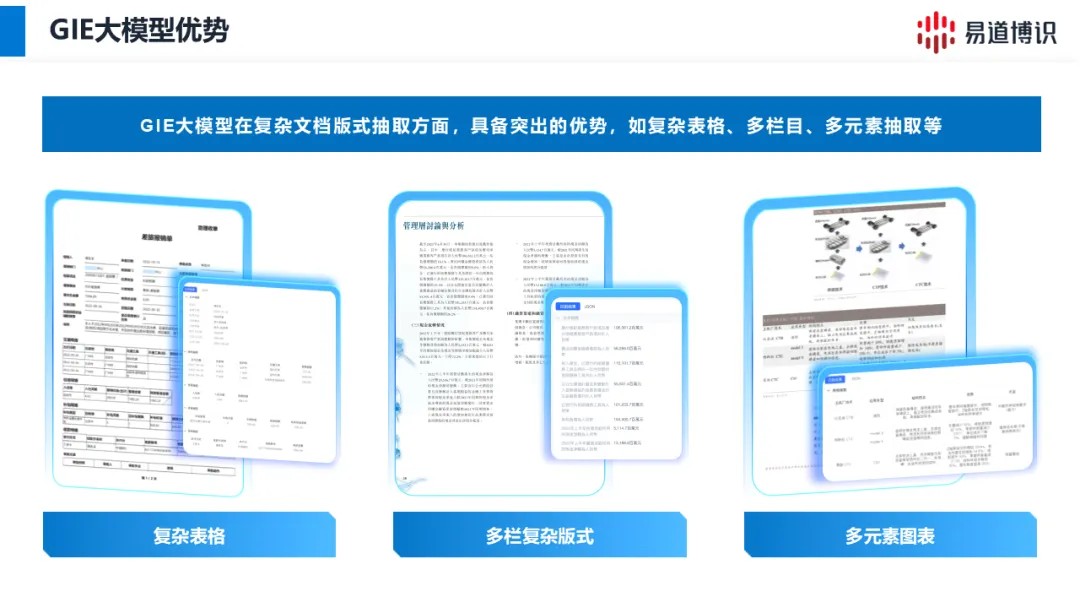
而随着以Transformer架构为代表的大模型的兴起,文档处理也迎来了新的发展机遇。大模型技术凭借其强大的语义理解能力、跨模态学习能力和泛化能力,能够有效克服传统OCR技术的局限性,实现对各种复杂场景文档的高精度、高效率识别和处理。易道博识正是敏锐地洞察到了大模型在文档智能领域的巨大潜力,推出了GIE大模型(OCR大模型)。
金融机构只需通过一个API接口,即可实现几乎所有金融业务场景涉及的文档类型的高精度识别,如财务发票、合同文本、法律文件、审计报告、理赔文件、项目文件、企业文档、医疗单据、财务报表、个人证件、机构证件、保险单据、订单表单等。
这极大地简化了系统集成和部署流程,降低了开发成本,让金融机构能够快速、便捷地享受到大模型带来的智能化升级红利。

例如在以往两录一校业务中,同一笔文档数据需要由两名不同的操作人员分别独立录入,由第三人对上述两人录入的数据进行核对校验,确保两次录入的数据一致。易道博识智能两录一校方案,方案采用GIE大模型和OCR小模型同时对一份文档进行整张识别录入,系统智能比对识别结果,大部分一致数据自动化入库,少量不一致则交由人工审核核验。 交叉校验构建数据质量防线,大幅提升业务效率。
易道博识与华为始终保持紧密的战略伙伴关系,共同致力于驱动金融行业的数智化转型升级,易道博识也期待以此为契机,与华为及更多生态伙伴深化交流,拓展合作,共谱智能金融自主创新发展的新篇章。





